

Im Berichtswesen gibt es oft die Notwendigkeit, häufig wiederkehrende Abfragen in speziellen Spaltenlayouts zu speichern.
Früher bot SuperX nur die Möglichkeit neue Masken zu erzeugen, oder Lesezeichen anzulegen.
In dem Modul können Sie auf der Basis des SuperX-Datenmodells
Hier eine Übersicht über die Architektur des Moduls im Kontext von SuperX:
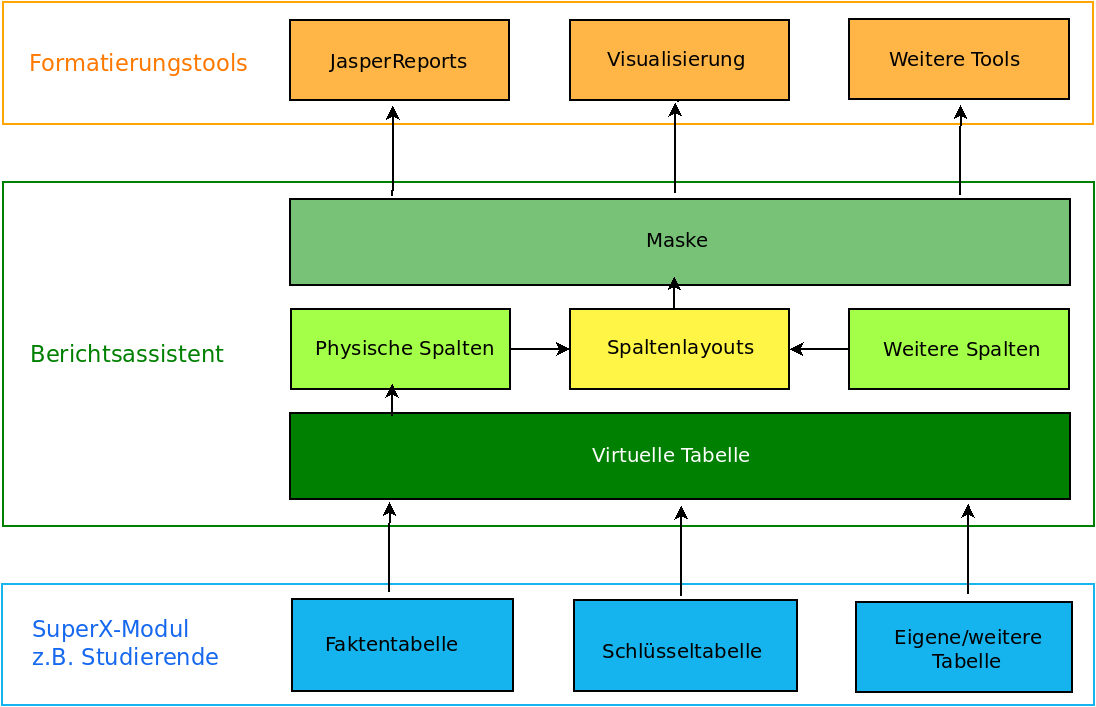
Die Basis bilden die vorhandenen SuperX-Module mit ihren Fakten- und Schlüsseltabellen. Häufig benötigte Tabellen und Spalten werden in einer "virtuellen Tabelle" gebündelt. Auf dieser virtuellen Tabelle können Spaltenlayouts definiert werden, die einerseits aus "physischen" Spalten bestehen können (z.B. Alter der Studierenden in Jahren), und andererseits aus weiteren, dynamisch ermittelten Spalten (z.B. Alterskohorte von 0-20,20-25 etc.). Die Spaltenlayouts werden in speziellen SuperX-Masken aufgerufen und können in anderen Formatierungstools (JasperReports oder Visualisierungen im VIZ-Modul) weiterverarbeitet werden.
Siehe auch:


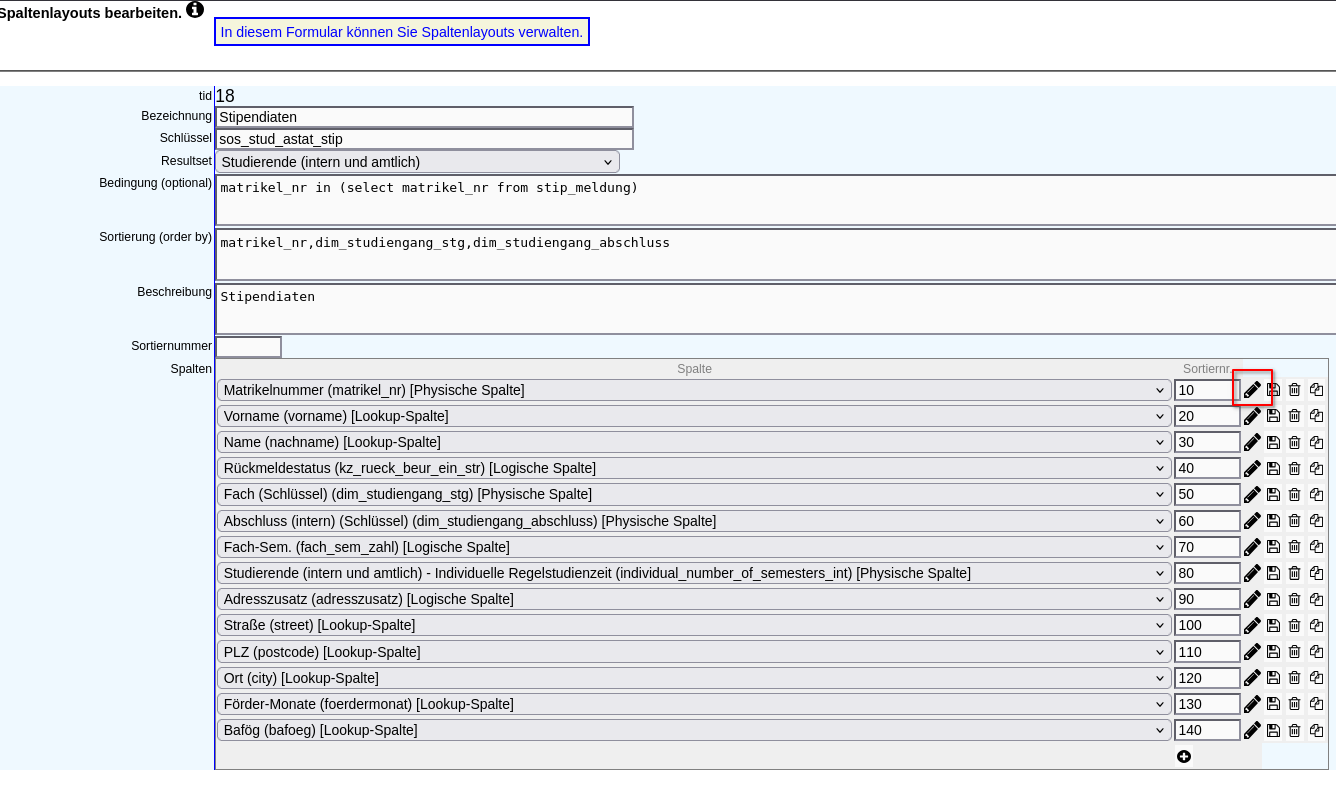
Bei der Zuordnung einer Spalte zu einem Spaltenlayout lässt sich ein Format-Code auswählen. Dieser führt, mit wenigen Ausnahmen, eine Typumwandlung durch. Zu den Ausnahmen weiter unten in diesem Abschnitt.
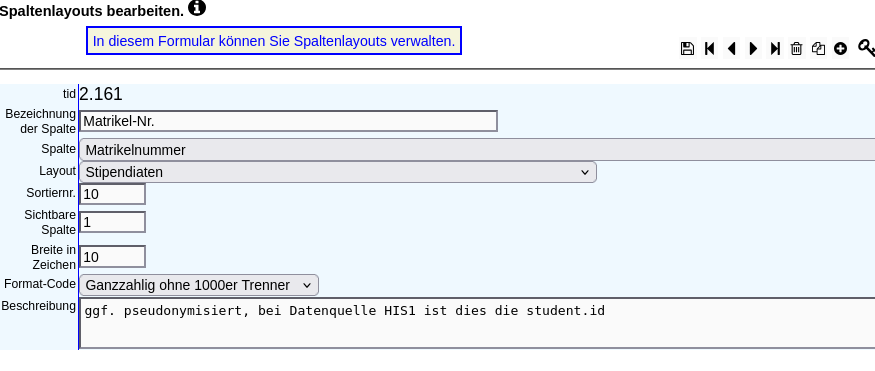
In folgendem Beispiel wir der Format-Code "Ganzzahlig ohne 1000er Trenner" gesetzt. Das kann zum Beispiel hilfreich sein, um Matrikelnummern ohne Tausendertrennzeichen anzuzeigen. Dabei wird integer zu varchar umgewandelt, wodurch der Tausendertrenner verschwindet.
Die beiden Format Codes "0-Werte ausblenden" und "0-Werte ausblenden (ganzzahlig)" stellen Ausnahmen dar. Sie dienen dazu, zu ermitteln, ob der Wert einer Spalte gleich 0 ist und falls ja, diesen 0-Wert auszublenden, das heißt auf null zu setzen. Das bedeutet, dass die Spalte einen numerischen Wert liefern muss, sonst kommt es zu einem SQL-Fehler. Falls der Wert ungleich 0 ist, kann, sofern erwünscht, der Wert zu integer umgewandelt werden. Dafür wird "0-Werte ausblenden (ganzzahlig)" genutzt. Falls die Spalte ihren Datentyp behalten soll, wird "0-Werte ausblenden" genutzt.
Folgende Maske dient dazu:

Durch Auswahl der Basistabelle kann die Anzeige der angebotenen Spaltenlayouts eingeschränkt werden.Dann wird ein neuer eindeutiger Schlüssel und Name vergeben, ebenso kann eine passende Erläuterung eingefügt werden. Ansonsten wird die Erläuterung des kopierten Layouts beibehalten.
Durch die Sicherheitsabfrage "Vorh. Layout überschreiben" wird verhindert, dass man aus Versehen ein Layout überschreibt.
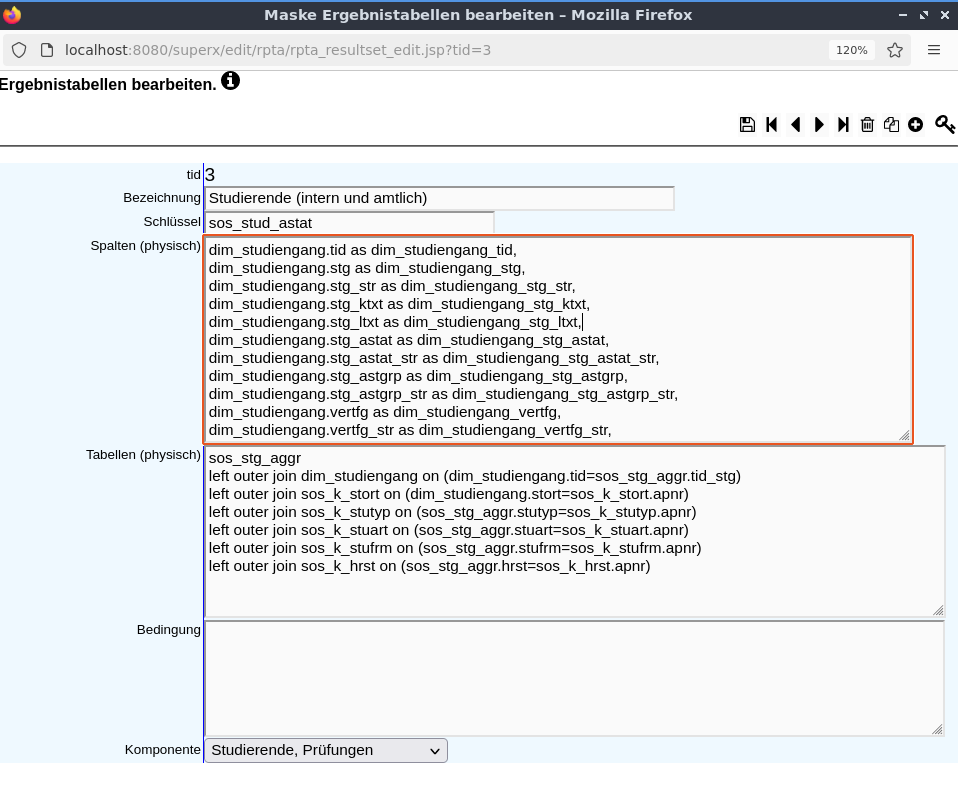
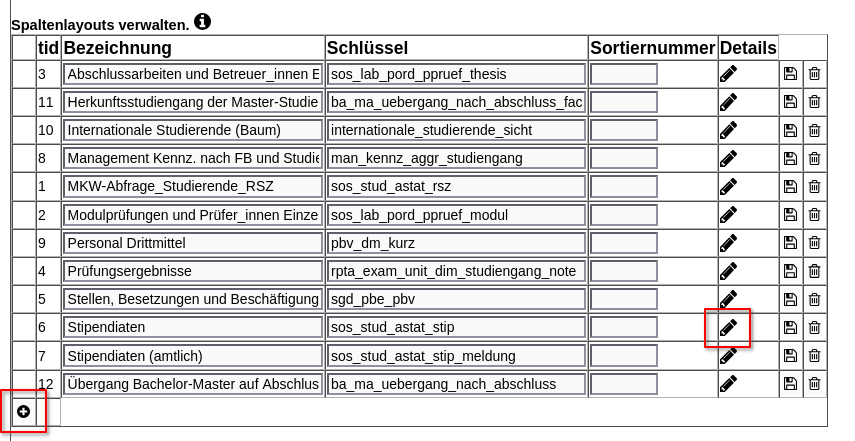
In der Ergebnistabelle

kann durch den Stift eine Bearbeitungsseite aufgerufen werden. Hier können - wie bereits unter spaltenlayout verwalten erklärt - alle Felder geändert und Spalten gelöscht werden. Man muss da natürlich bei berechneten Spalten darauf achten, diese bei Löschungen anzupassen!

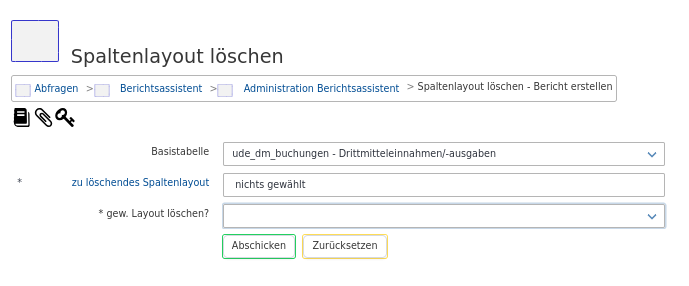
Auch hier kann durch eine Angabe der Basistabelle die Anzeige der Spaltenlayouts eingeschränkt werden. Man muss aktiv ein J auswählen, damit ein versehentliches Löschen verhindert wird.
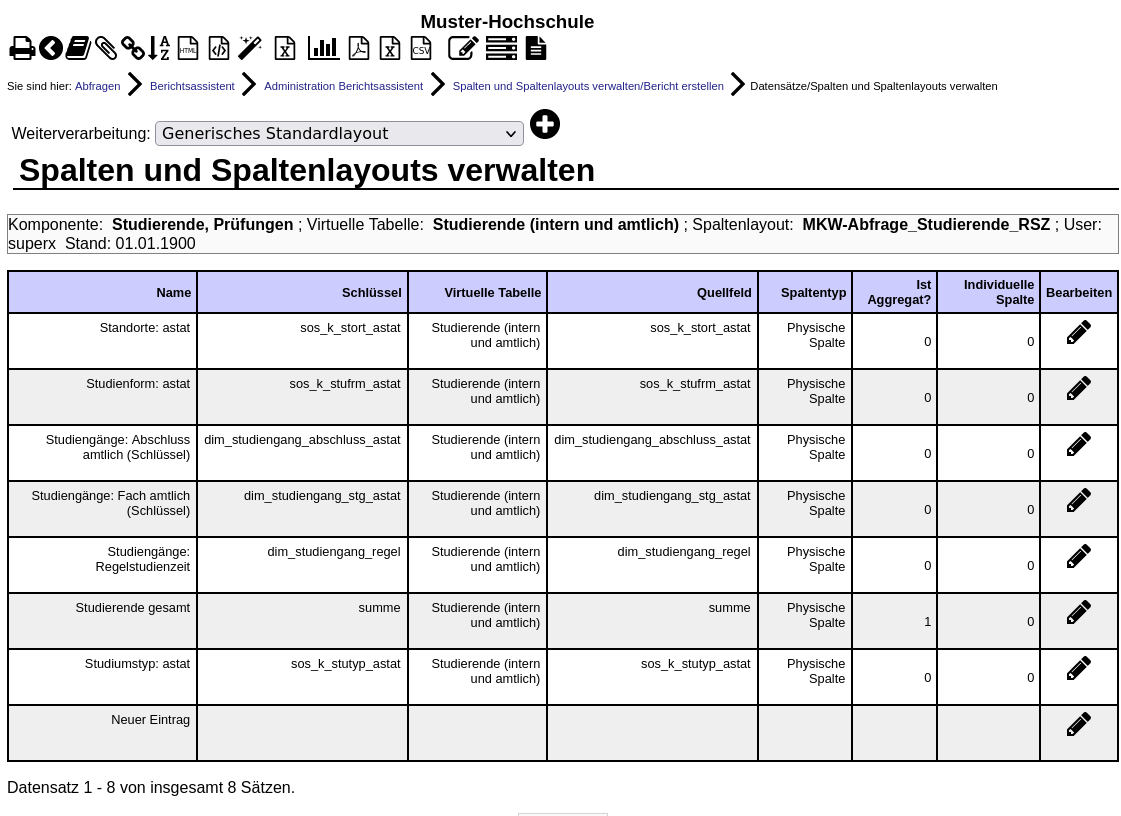
Es gibt folgende Spaltentypen:
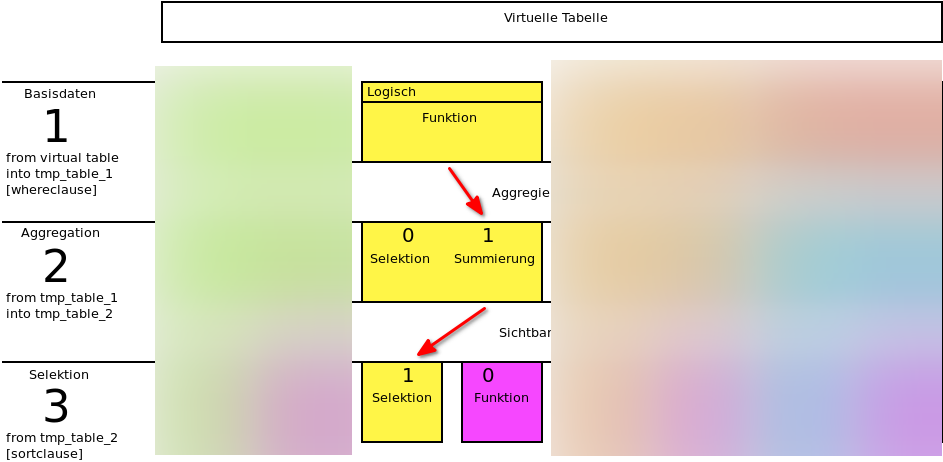
Dieser Abschnitt bietet eine kurze Übersicht, wie die Spalten verarbeitet werden. Sowohl Grafik als auch Text stellen nicht die exakte Funktion des zugehörigen Codes dar. Sie stellen eine Annäherung dar, welche versucht, die Komplexität möglichst einfach darzustellen. Zum besseren Verständnis sind weiter unten Beispiele aufgeführt.
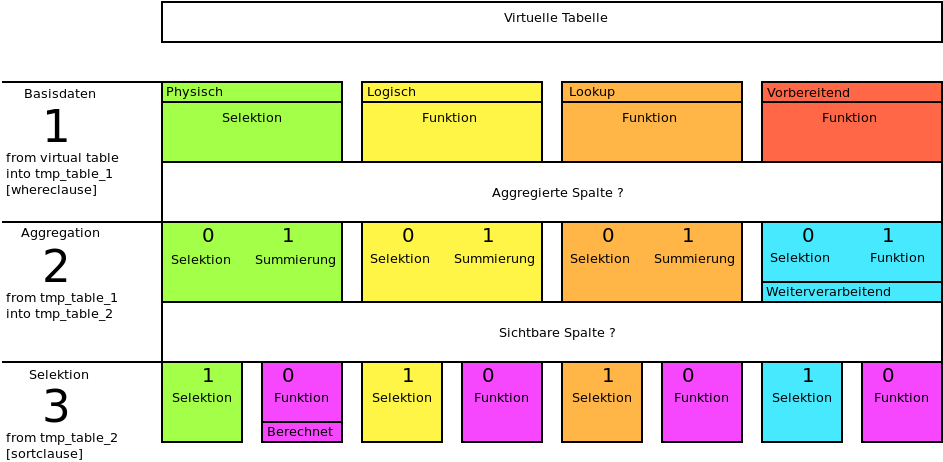
Im ersten Schritt wird eine temporäre Tabelle (tmp_table_1) mit allen Spalten des Spaltenlayouts erstellt, sowohl später sichtbare als auch unsichtbare Spalten. Dabei werden entweder
Im zweiten Schritt werden die Daten aus der in Schritt 1 erstellten tmp_table_1 in eine weitere temporäre Tabelle (tmp_table_2) überführt und dabei aggregiert. Welche Spalten aggregiert werden, wird über das Merkmal Aggregierte Spalte festgelegt. Dabei wird entweder
Bei der Summierung wird der angegebene Feldname (Ziel) in eine sum()-Funktion eingefügt. Bei einer Funktion wird die Eingabe im Feld Funktion genutzt.
Schritt 3: SelektionIm dritten Schritt findet die finale Selektion statt. Jede Spalte, deren Merkmal Sichtbare Spalte auf 1 gesetzt ist, wird selektiert. Um bei der Selektion noch eine Berechnung oder Änhliches vorzunehmen, wird das Merkmal Sichtbare Spalte auf 0 gesetzt und eine Berechnete Spalte angelegt. Es wird dann die Funktion der Berechneten Spalte in den select geschrieben.
Zur Konfiguration werden folgende Maßnahmen getroffen:
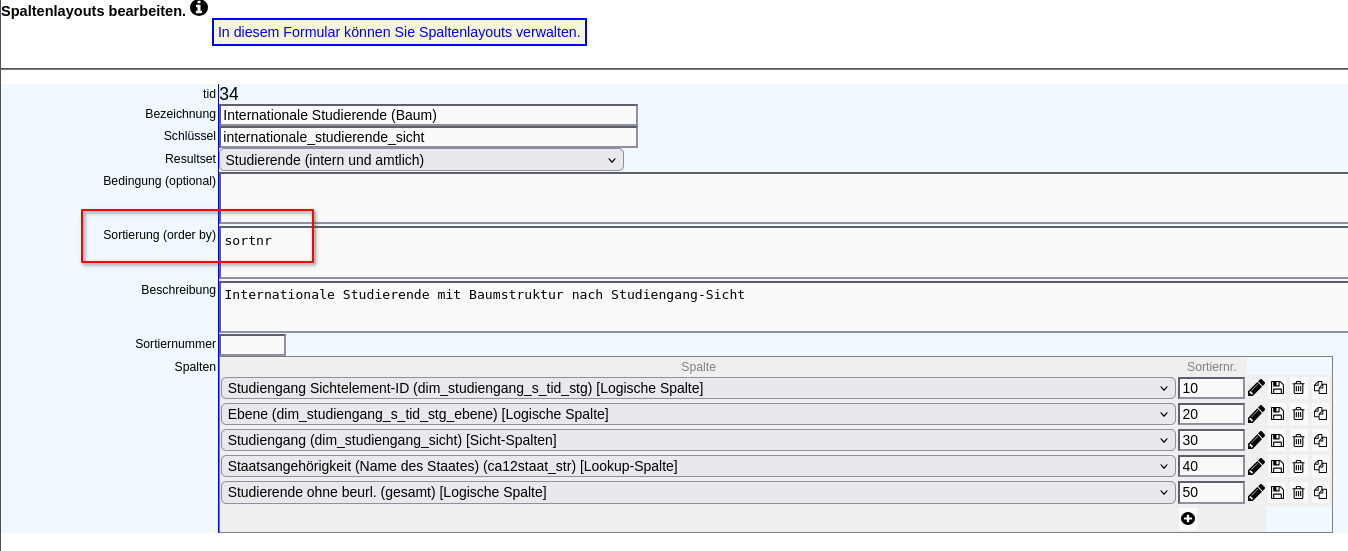
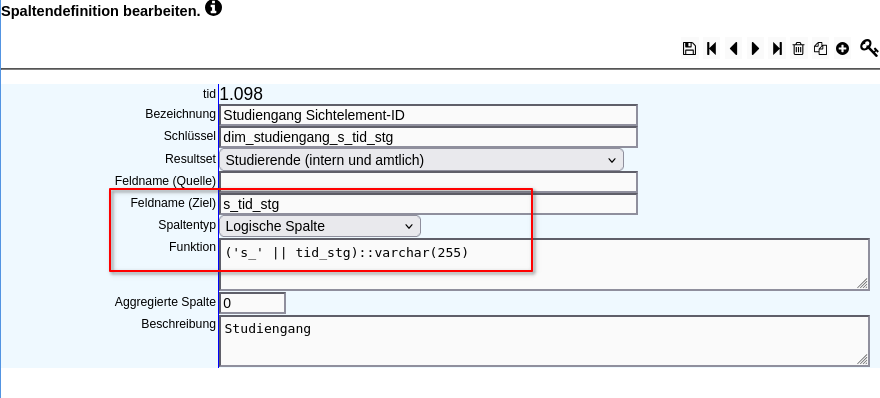
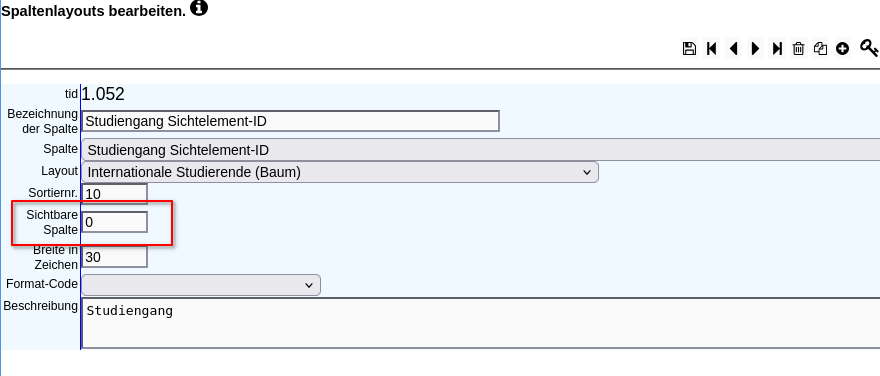
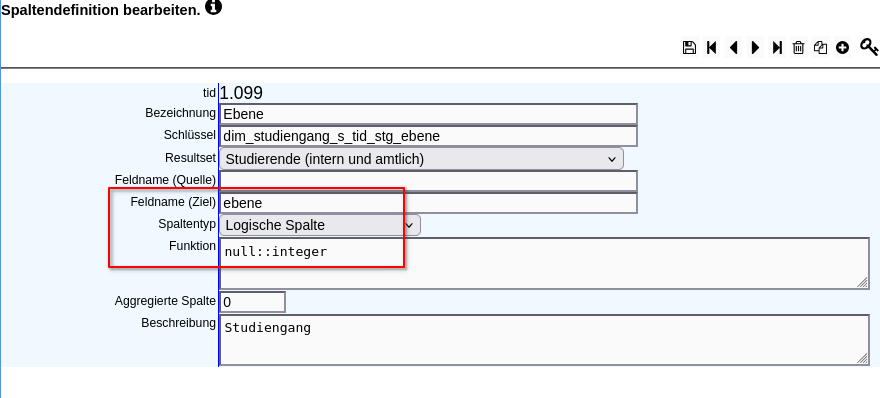
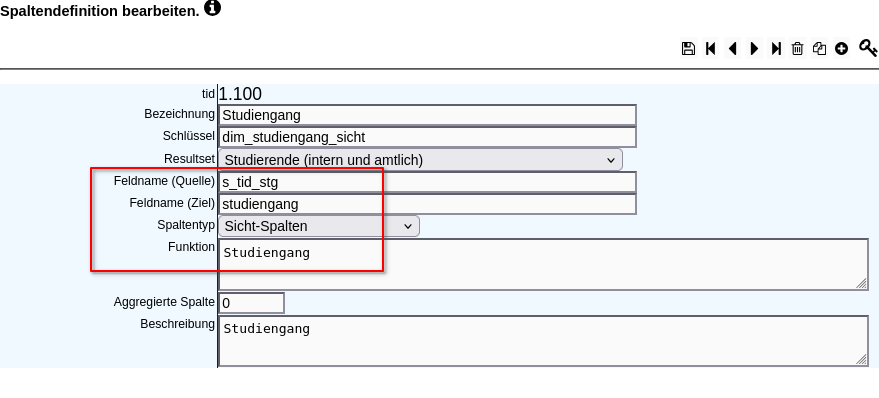

Folgend ein funktionierendes Beispiel. Die Sicht würde normalerweise beim Fach enden. Jedoch wird eine "Sicht-Spalte mit zusätzlicher Kindebene" verwandt und dadurch eine zusätzliche Ebene für die Differenzierung nach Staatsangehörigkeit angelegt:
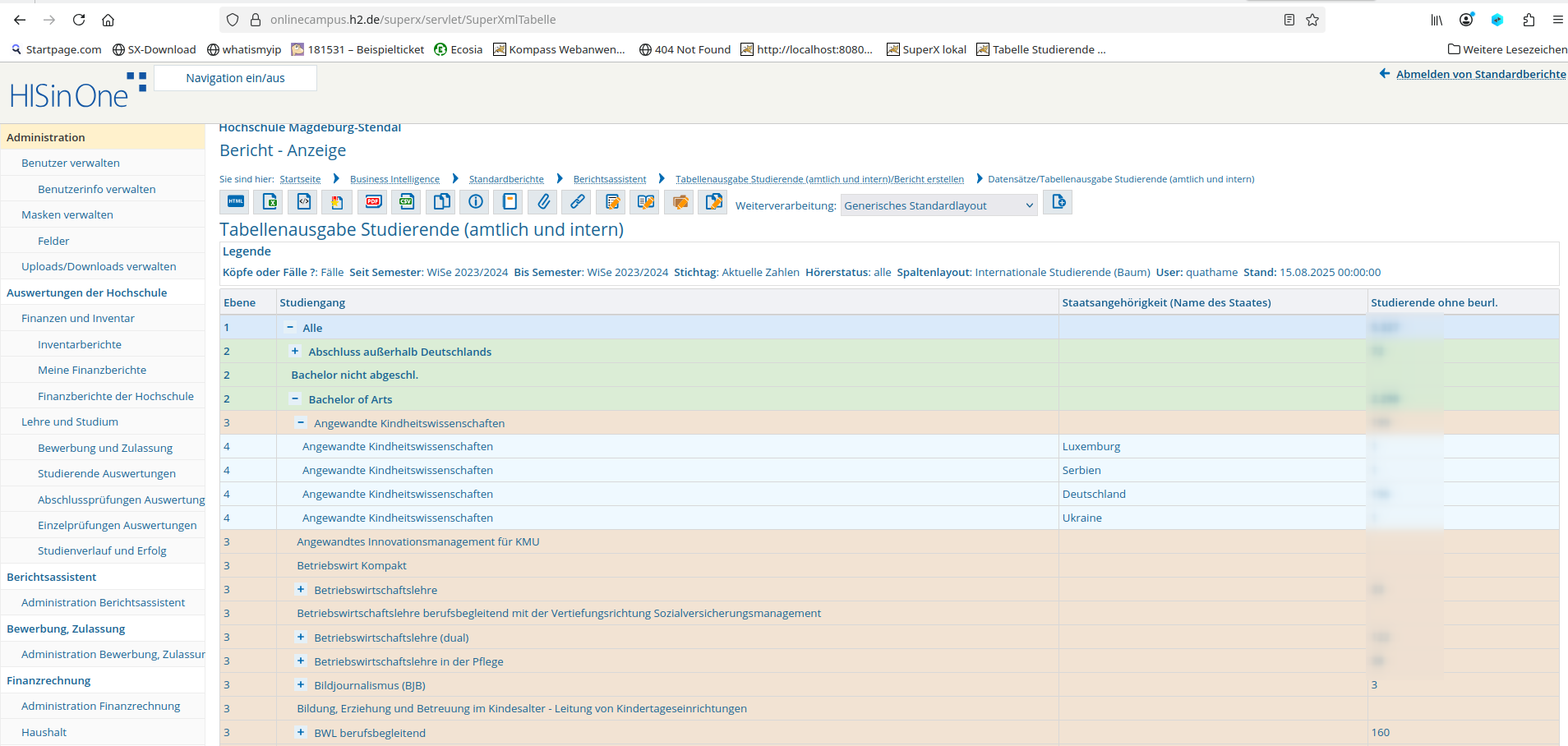
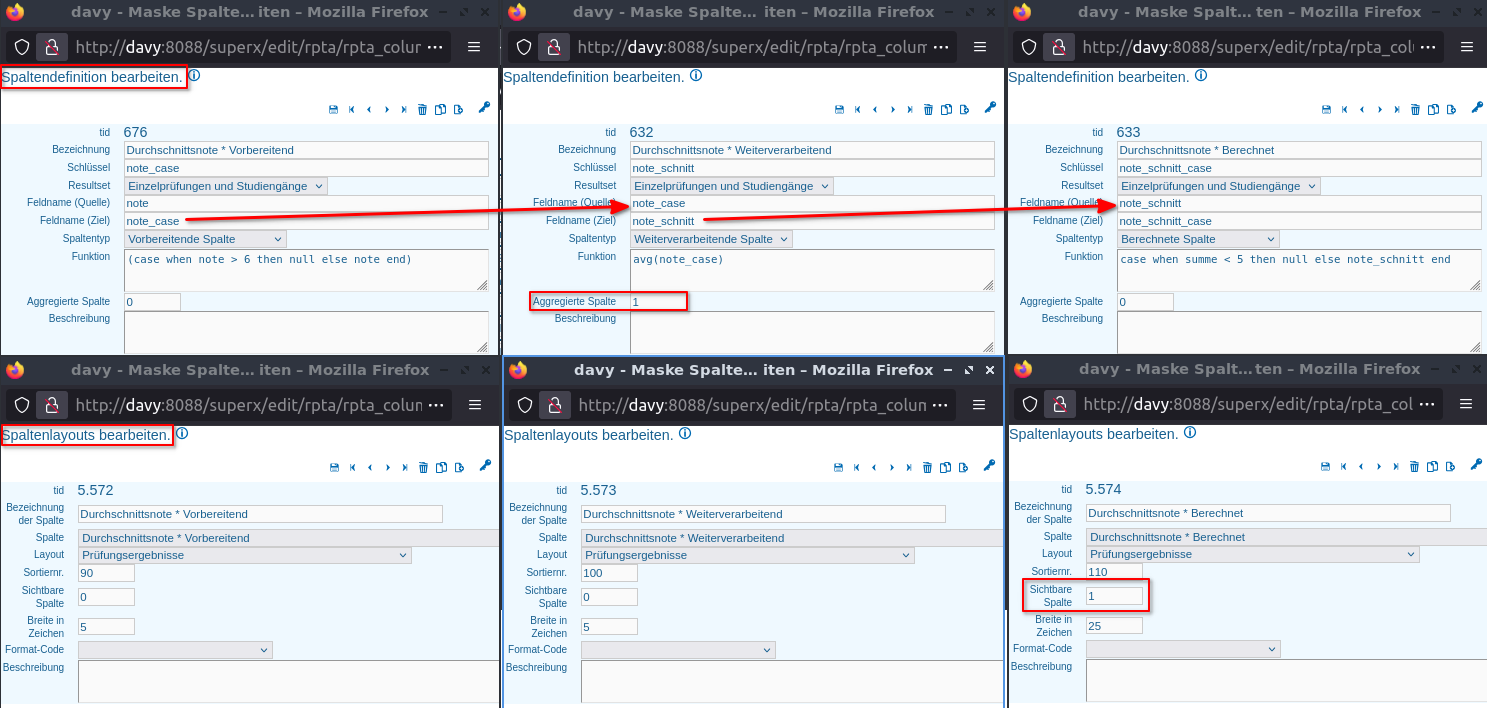
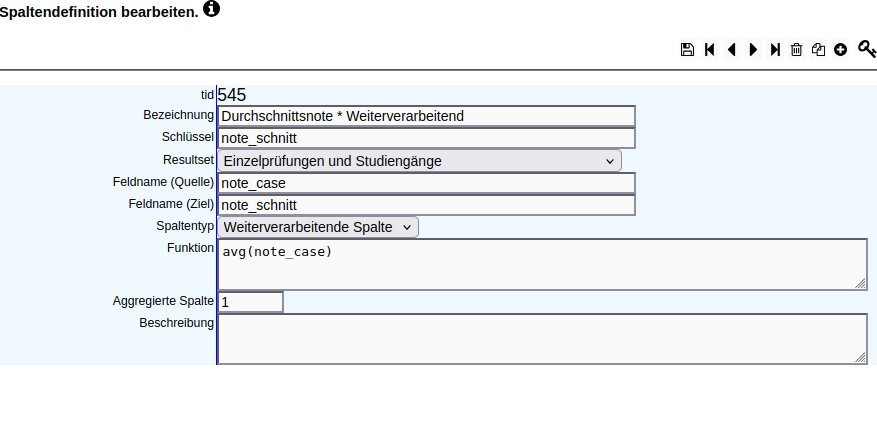
Es soll die Durchschnittsnote berechnet und ausgegeben werden, sofern mehr als 4 Personen an der Prüfung teilgenommen haben.
Dafür werden 3 Spalten angelegt:

Die Vorbereitende Spalte beinhaltet eine case-when-Bedingung, damit bspw. unbekannte Noten (note=8) rausgefiltert werden. Der Feldname (Quelle) kann leer bleiben. Der Feldname (Ziel) muss gefüllt werden. Bei der Weiterverarbeitenden Spalte wird als Feldname (Quelle) der Feldname (Ziel) der Vorbereitenden Spalte eingetragen. Das Merkmal Aggregierte Spalte wird auf 1 gesetzt und die gewünscht Funktion eingetragen. Es folgt die Berechnete Spalte, welche als Feldname (Quelle) den Feldname (Ziel) der Weiterverarbeitenden Spalte bekommt. Die Funktion sorgt dafür, dass der Notenschnitt nur dann ausgegeben wird, wenn mindestens 5 Prüfungen vorhanden sind. Es wird das Merkmal Sichtbare Spalte auf 1 gesetzt, damit die Ausgabe in der Ergebnistabelle erfolgt.
Es soll anhand des Prüfungsvermerkes ermittel werden, wie viele Studierende nicht zur Prüfung erschienen sind.
Dafür wird eine eine Spalte angelegt:
In der Funktion wird eine case-when-Bedingung angelegt, um die richtigen Prüfungsvermerke zu filtern. Außerdem wird das Merkmal Aggregierte Spalte auf 1 gesetzt. Für eine logische Spalte bedeutet das, dass summiert wird. Damit die Summe in der Ergebnistabelle erscheint, wird das Merkmal Sichtbare Spalte auf 1 gesetzt.
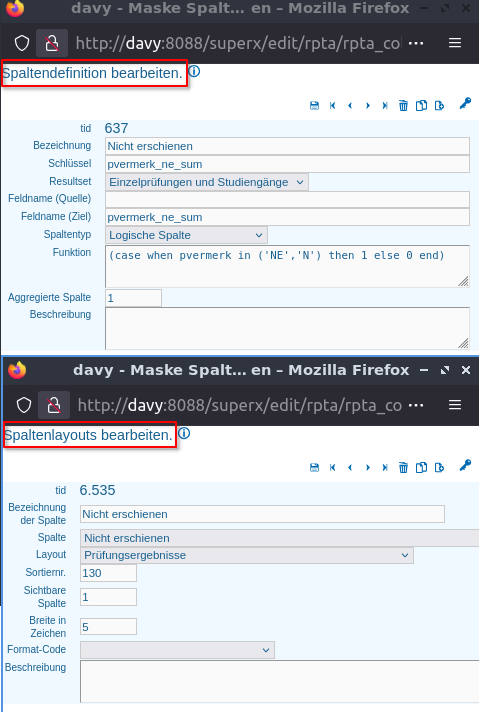
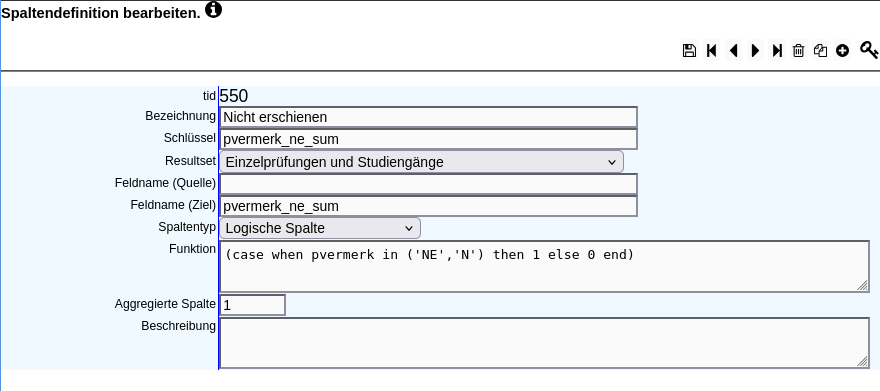
pvermerk in ('NE','N') ist die Bedingung. Wenn pvermerk 'NE' oder 'N' ist, dann ist die Bedingung wahr. Falls sie wahr ist, wird eine 1 hinterlegt -- then 1 . Ansonsten wird eine 0 hinterlegt -- else 0 . Dadurch kann anschließend gezählt werden, wie oft die Bedingung erfüllt wurde, das heißt in diesem Beispiel, wie oft ein Prüfungsvermerk 'NE' oder 'N' ist.
Weitere Erläuterung siehe
https://www.postgresql.org/docs/current/functions-conditional.html#FUNCTIONS-CASE|Postgres-Doku
In der Auslieferung gibt es eine Beispielanwendung, die Studierendenauswertungen flexibel für Landes- oder interne Zwecke ausgeben kann.
Das Ziel ist z.B. die beigefügte Tabelle fürs Ministerium in NRW:
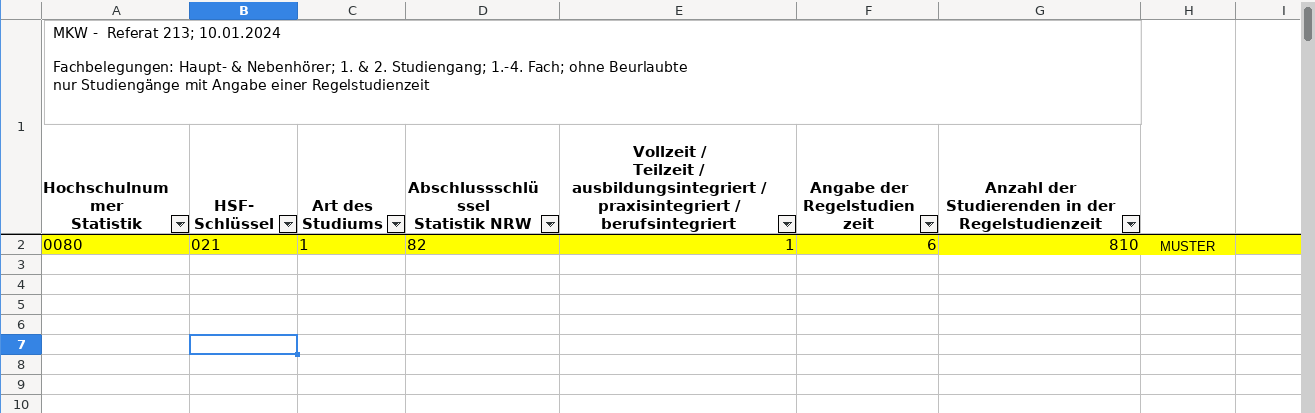
Die Datengrundlage ist eine Tabelle mit Studierendendaten. Diese wird im folgenden beschrieben.
Nach Login mit einer Admin-Kennung haben Sie Zugriff auf das Menü Abfragen - Berichtsassistent - Administration Berichtsassistent, dort die Maske Spalten und Spaltenlayouts verwalten. Dort unter "Weitere Einstellungen" finden Sie die Verwaltung der virtuellen Tabellen.

Die virtuelle Tabelle "Studierende amtlich und intern" beinhaltet
Hintergründe zu den amtlichen Schlüsseln erfahren Sie in diesem Lehrfilm:
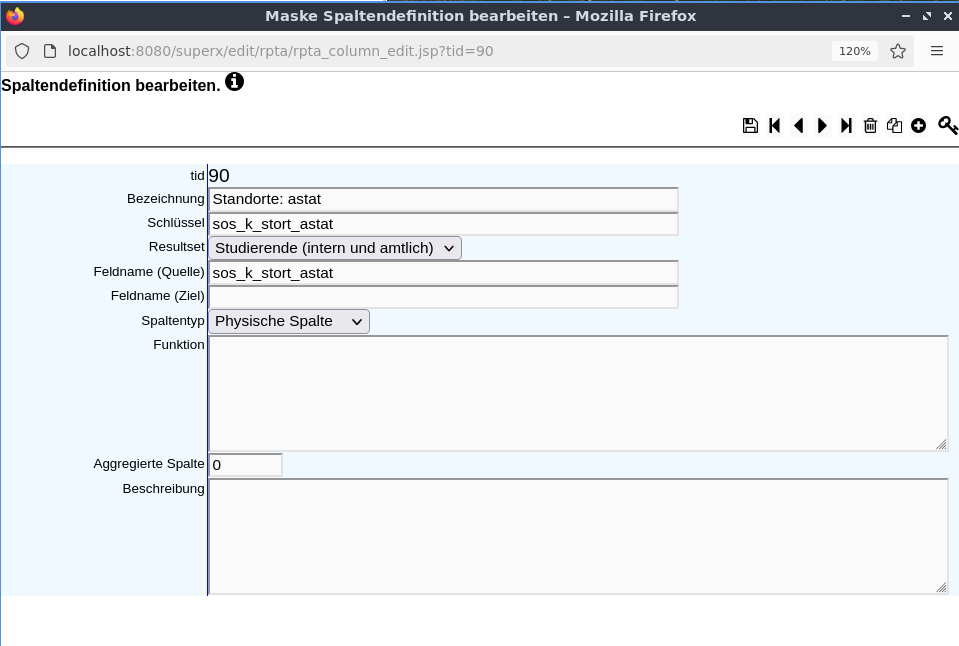
Das Detailformular zeigt die Quelltabellen und Felder:
Dieses Beispiel sollten Sie nicht ändern, es dient nur als Beispiel in der Auslieferung.
Ausgehend vom obigen Beispiel-Muster benötigen wir eine Tabelle mit Studierendensummen mit einem Filter auf
Die Tabelle enthält folgende Spalten:
Die Benennung der Spalten sollte exakt mit dem Muster übereinstimmen.
Zunächst die Tabellendefinition: Filter wie Stichtag, Hörerstatus und Status können wir wie gewohnt in der Maske als Felder anbieten, und die Filter
definieren wir direkt im Spaltenlayout. Wir gehen dazu in das Menü Abfragen - Berichtsassistent - Administration Berichtsassistent, dort die Maske Spalten und Spaltenlayouts verwalten. Dort unter "Weitere Einstellungen" finden Sie die Verwaltung der Spaltenlayouts:

Das Feld "Bedingung (optional)" definiert die Filter auf der virtuellen Tabelle. Da manche Hochschulen Studiengänge ohne Regelstudienzeit mit einem sehr hohen Wert versehen (z.B. 99), wird ein Filter auf eine "übliche" Regelstudienzeit zwischen 1 und 20 Semestern gesetzt.
Im Beschreibungsfeld darunter wird eine textuelle Beschreibung im Sinne einer Legende angeboten. Diese wird in der späteren Berichtsausgabe dann unter der Legende erscheinen.
Die eigentlichen Spalten werden in dem Unterformular angezeigt, mit Klick auf die jew. Details können Sie die Bezeichnung der Spalte und Layoutmerkmale angeben, sowie einen Erläuterungstext:

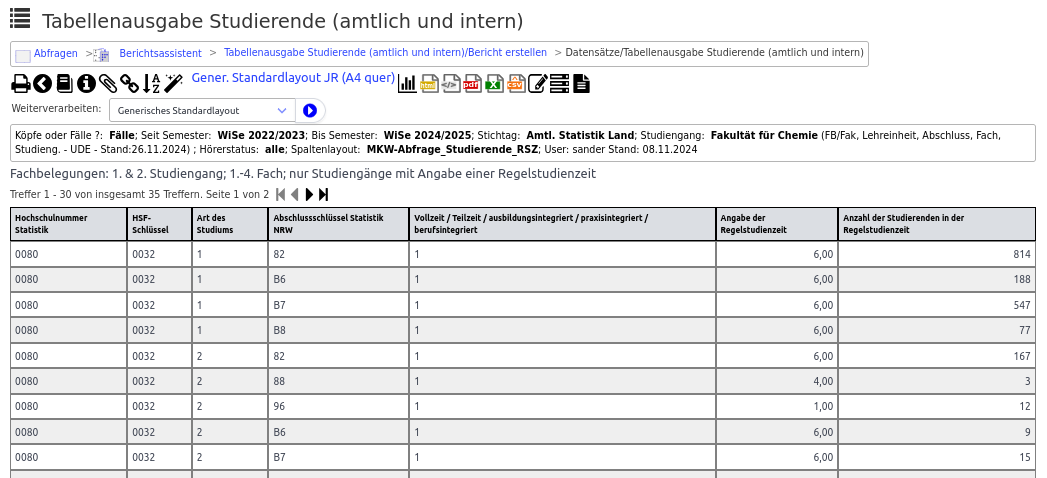
Den fertigen Bericht können Sie hier abrufen: In der Maske definieren Sie die Ergebnismenge
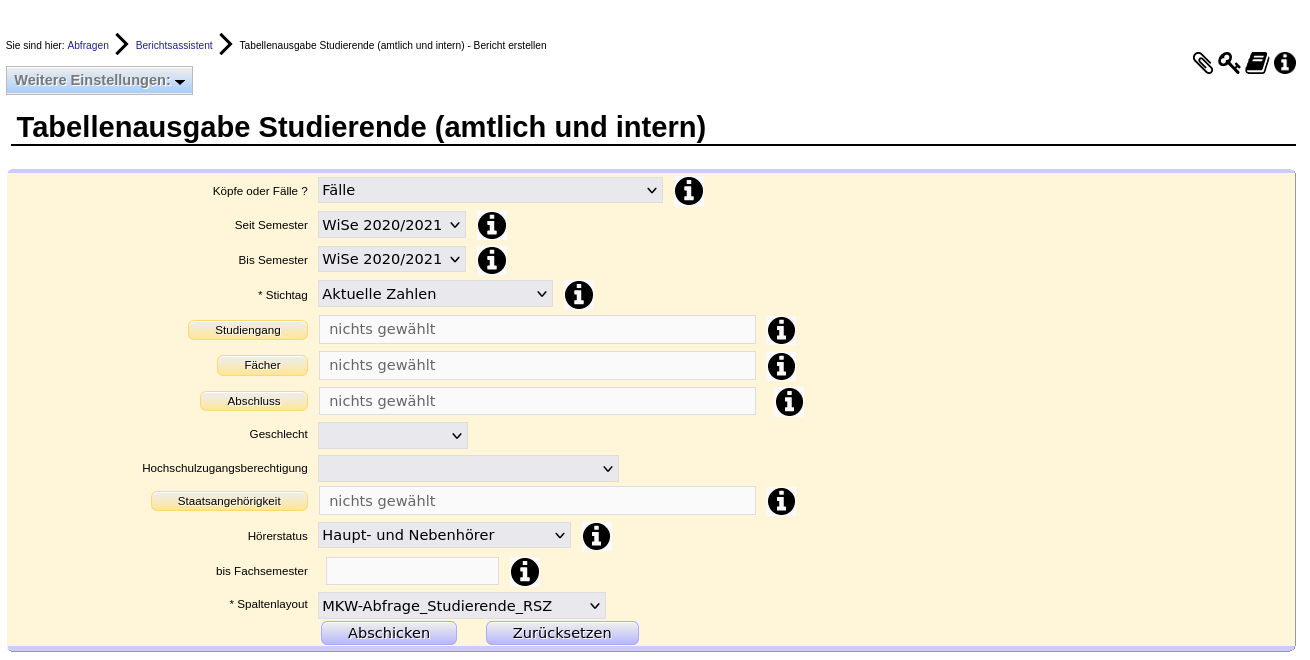
und die Tabelle gibt die Studierendensummen exakt im Layout des Musters aus:

Die Sortierung erfolgt in der Reihenfolge der Spalten jeweils aufsteigend.
Hinweis: Das SuperX-Modul RPTA umfasst einen Berichtsassistenten mit Exportfunktionen.
Der Berichtsassistent bietet die Möglichkeit, durch Auswahl der Spalten, die Ergebnisse zu Studierenden sehr flexibel selbst zu gestalten.

Wenn keine Felder ausgewählt werden, ist das Ergebnis:
Dieses Layout wurde speziell für den Vergleich mit der amtlichen Statistik erstellt. Bisher gibt es Layouts zu folgenden Themen

Dazu finden Sie auch die folgenden 2 Lehrfilme:
Mit diesem Berichts(Export-)assistenten werden ansprechend formatierte text- oder tabellenorientierte Layouts erzeugt.
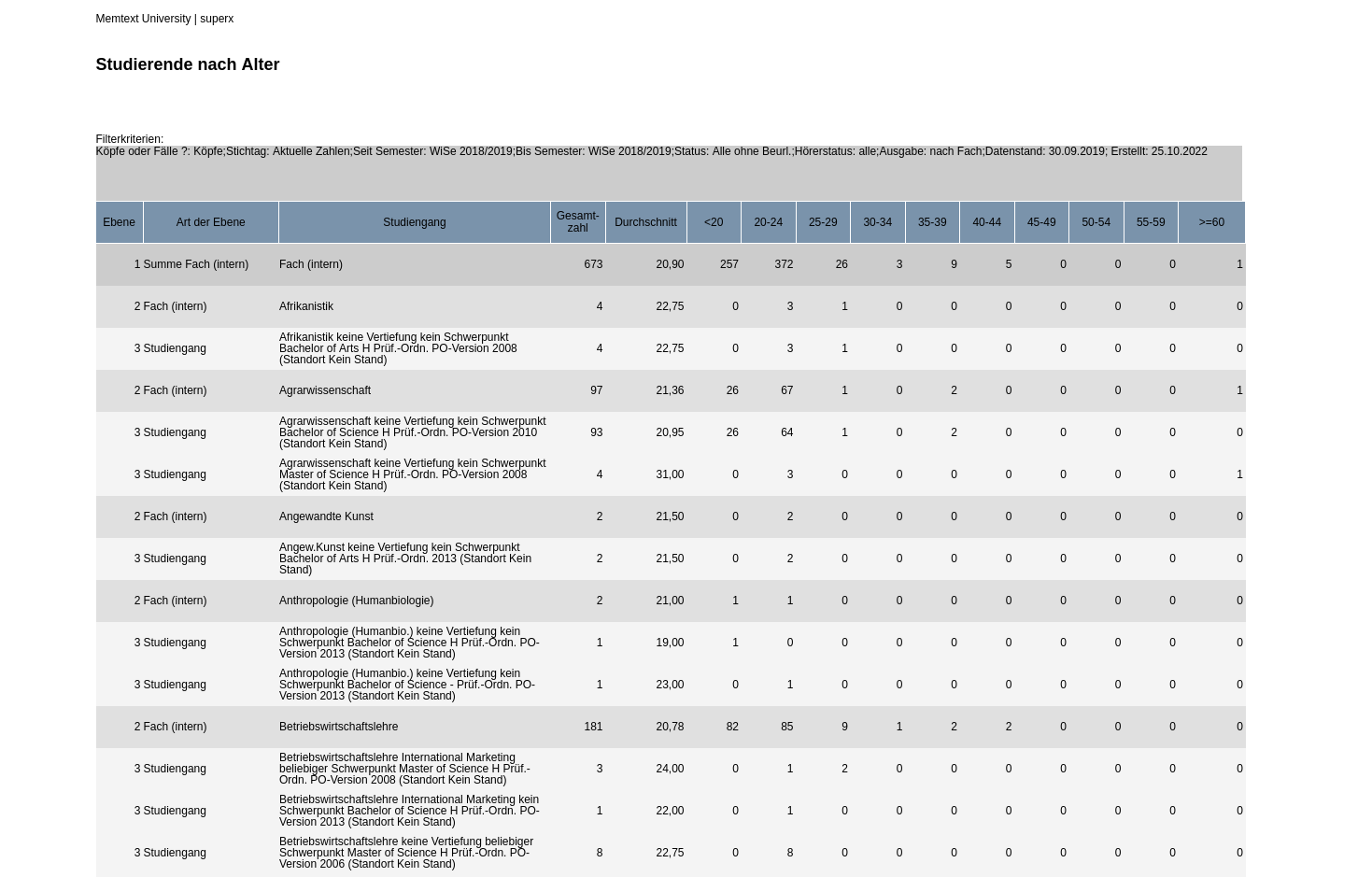
Rufen Sie zunächst eine Maske auf und zeigen Sie die Ergebnistabelle an, z.B. Studierende nach Alter:
Wählen Sie dann den in der obigen Abbildung rot umrandeten "Zauberstab".
Mit Klick auf den "Zauberstab" erhalten Sie

Die Exportmaske bietet drei Menüpunkte an:
Mit dem Abschicken des Formulars erhalten Sie bei Formaten außer HTML einen Download-Dialog, und z.B. eine Datei wie folgt:
Sobald das RPTA-Modul installiert ist, werden der Excel- und der pdf-Export-Button zu Shortcuts.

Mit Klick auf den in der obigen Abbildung rot umrandeten "xls-Exportbutton" erhalten Sie z.B. folgendes Auswahlfenster, in dem Sie wählen können:

Wenn Sie den JRXML-Quellcode herunterladen, koennen Sie das Berichtslayout mit JasperSoft Studio weiter verfeinern. Details siehe im JasperReports-Handbuch.
Wenn 'srcfieldname' oder 'targetfieldname' falsch oder nicht gesetzt sind, kann es passieren, dass bestimmte Spalten bzw. Spaltenbezeichnung mehrfach vorkommen. Das führt zum Fehler.
Es gibt eine preparingColumn, welche geschlecht=weiblich markieren soll (case when geschlecht=2 then 1 else 0 end). Es wird "targetfieldname":"geschl_w" gesetzt.
In einer processingColumn soll anschließend gezählt werden. Es wird "srcfieldname":"geschl_w" gesetzt. Das ist richtig. Aber falls vergessen wird einen targetfieldname zu setzten, dann wird automatisch srcfieldname=targetfieldname. Daraus resultiert der genannte Fehler.
Lösung: Für die processingColumn wird ein targetfieldname gesetzt, welcher sich vom srcfieldname unterscheidet.
Eine processingColumn soll summieren. Es wird "col_function":"sum" gesetzt. Das wirft den genannten Fehler aus (ERROR: column "sum" does not exist), weil sum dann als Spalte gesucht wird (sum as bewerbungen_w).
Lösung: Für die Aggregatfunktion der colfunction wird der srcfieldname angegeben, bspw. "col_function":"sum(geschl_w)".