Es wird ein neuer User schmidt angelegt. Dafür wird zunächst das User Management geöffnet.
Tipps und Tricks im Umgang mit SQL
Where Bedingungen mit verketteten Strings (Concat) verlangsamen die Laufzeit beträchtlich. Beispiel:
select distinct sgd_join_id,pbe_serial,pbe_von,pbe_bis,merkmal_bis+1,'Folgetag Endzeitpunkt ' quelle from tmp_zeitraum1 where merkmal_bis<pbe_bis and sgd_join_id::varchar(90)||pbe_serial::varchar(90)||merkmal_bis not in (select sgd_join_id::varchar(90)||pbe_serial::varchar(90)||merkmal_von from tmp_zeitraum1_copy);
Schneller geht es mit "exists", hier ein Beispiel für Postgres:
select distinct sgd_join_id,pbe_serial,pbe_von,pbe_bis,merkmal_bis+1,'Folgetag Endzeitpunkt ' quelle from tmp_zeitraum1 where merkmal_bis<pbe_bis and not exists (select 1 from tmp_zeitraum1_copy c where tmp_zeitraum1.sgd_join_id = c.sgd_join_id and tmp_zeitraum1.pbe_serial = c.pbe_serial and tmp_zeitraum1.merkmal_bis= c.merkmal_von)
meine kann auch Informix, noch mal checken ggfs.
Ab PostgreSQL 9.3
https://www.postgresql.org/docs/current/queries-table-expressions.html#QUERIES-LATERAL
Wenn Sie eine Spalte mit einem Subselect ändern wollen, geht dies mit Variante 1
Aber Achtung: wenn ein solcher Update in Variante 1 beim Subselect einen Fehler "A subquery has not returned exactly one row" liefert, entfällt dieser bei Variante 2a - Postgres nimmt einfach den "erstbesten" Datensatz.
<#if SQLdialect='Postgres'<#if SQLdialect='Postgres'> UPDATE tmp_buch SET z_name = gxstage_zp.druck, z_name2 = gxstage_zp.lang_1 FROM gxstage_zp WHERE z_nr is not null and gxstage_zp.apnr = tmp_buch.z_nr; <#else>
UPDATE tmp_buch SET (z_name, z_name2) = ((SELECT druck, lang_1 FROM gxstage_zp WHERE gxstage_zp.apnr=tmp_buch.z_nr)) WHERE z_nr is not null;
Die WITH-Klausel erlaubt es, ohne temp.Tabellen Resultsets zwischenzuspeichern, vergl. postgres with.
statt
update ${tabellenname} set ${cifx_key.name}=(select min(apnr) from trans_cifx Z
where Z.key=${cifx_key.key}
and Z.systeminfo_id=${systeminfo_id}
and Z.sourcesystem_id=${tabellenname}.${cifx_key.name}
and Z.sourcesystem=${Quellsystem_var} --hisinone
);
schneller
with tmp_${cifx_key.key} (${cifx_key.name}, apnr) as (
select S.${cifx_key.name}, min(apnr) as apnr
from trans_cifx Z inner join ${tabellenname} S
on Z.sourcesystem_id=S.${cifx_key.name}
where Z.key=${cifx_key.key}
and Z.systeminfo_id=${systeminfo_id}
and Z.sourcesystem=${Quellsystem_var}
group by S.${cifx_key.name}
update ${tabellenname} set ${cifx_key.name}=(select apnr from tmp_${cifx_key.key}
where ${tabellenname}.${cifx_key.name} = tmp_${cifx_key.key}.${cifx_key.name})
where ${tabellenname}.${cifx_key.name} in (select ${cifx_key.name} from tmp_${cifx_key.key})
evtl noch schneller:
with...
update ${tabellenname} set ${cifx_key.name}=tmp_${cifx_key.key}.apnr
from tmp_${cifx_key.key} where ${tabellenname}.${cifx_key.name} = tmp_${cifx_key.key}.${cifx_key.name}
and ${tabellenname}.${cifx_key.name} in (select ${cifx_key.name} from tmp_${cifx_key.key})
Beispiel:
create index ix_tmp_erg1 on tmp_erg (buchungsab_fb); with tmp_fb (buchungsab_fb, ktobez) as ( select F.buchungsab_fb, max(ktobez) as ktobz from fin_buchab_fb F inner join tmp_erg T on T.buchungsab_fb=F.buchungsab_fb where F.jahr=<> group by 1) update tmp_erg T set buchungsab_fb_bez=tmp_fb.ktobez from tmp_fb where T.buchungsab_fb = tmp_fb.buchungsab_fb;
Postgres erlaubt auch rekursive Suche, hier ein Beispiel für das Organigramm:
with recursive org_rec (ebene,name,key_apnr,parent ,gueltig_seit,gueltig_bis,sort1) as (select 1 as ebene,O.name, O.key_apnr,O.parent ,O.gueltig_seit,O.gueltig_bis,trim(O.key_apnr) as sort1 from organigramm O where O.parent is null and today() between O.gueltig_seit and O.gueltig_bis union all (select R.ebene +1 as ebene,O2.name, O2.key_apnr,O2.parent ,O2.gueltig_seit,O2.gueltig_bis, R.sort1 || '_' || trim(O2.key_apnr) from organigramm O2,org_rec R where R.key_apnr=O2.parent and today() between R.gueltig_seit and R.gueltig_bis and today() between O2.gueltig_seit and O2.gueltig_bis ) ) --search depth first by name set sort1 select ebene,trim(name) as name,trim(key_apnr) as key,trim(parent) as parent,trim(sort1) as sort1 from org_rec order by sort1;
ergibt z.B.
ebene | name | key | parent | sort1 ------+--------------------------+---------+--------+------------------- 1 | Universität | 000 | | 000 2 | Lehre Hochschule | _9000 | 000 | 000__9000 3 | 01- WISO-Fakultät | 01 | _9000 | 000__9000_01 3 | 02- Rechtswiss. F. | 02 | _9000 | 000__9000_02 3 | 03- Medizinische F. | 03 | _9000 | 000__9000_03 3 | 04- Philosophische F. | 04 | _9000 | 000__9000_04 3 | 05- Math.-Nat. F. | 05 | _9000 | 000__9000_05 3 | 06- Humanwiss. F. | 06 | _9000 | 000__9000_06
Dieses Resultset könnte man direkt in Sichten als Quelle nutzen.
Postgres unterstützt seit 9.5 auch Kreuztabellen. Zuerst muss man das contrib-Paket installieren:
apt-get install postgresql-contrib
und dann in der DB die extension aktivieren:
CREATE EXTENSION tablefunc;
Beispiel:
CREATE TABLE ct(id SERIAL, rowid TEXT, attribute TEXT, value TEXT);
INSERT INTO ct(rowid, attribute, value) VALUES('test1','att1','val1');
INSERT INTO ct(rowid, attribute, value) VALUES('test1','att2','val2');
INSERT INTO ct(rowid, attribute, value) VALUES('test1','att3','val3');
INSERT INTO ct(rowid, attribute, value) VALUES('test1','att4','val4');
INSERT INTO ct(rowid, attribute, value) VALUES('test2','att1','val5');
INSERT INTO ct(rowid, attribute, value) VALUES('test2','att2','val6');
INSERT INTO ct(rowid, attribute, value) VALUES('test2','att3','val7');
INSERT INTO ct(rowid, attribute, value) VALUES('test2','att4','val8');
SELECT *
FROM crosstab(
'select rowid, attribute, value
from ct
where attribute = att2 or attribute = att3
order by 1,2')
AS mycrosstab(row_name text, category_1 text, category_2 text, category_3 text);
row_name | category_1 | category_2 | category_3
----------+------------+------------+------------
test1 | val2 | val3 |
test2 | val6 | val7 |
Beispiel für SuperX:
SELECT * from crosstab( 'select sem_rueck_beur_ein::varchar(255) as sem_rueck_beur_ein,geschlecht::varchar(255) as geschlecht, sum(summe)::integer as summe FROM kenn_stg_aggr group by 1,2 order by 1,2' ) AS ct(sem_rueck_beur_ein varchar(255), geschlecht_m integer,geschlecht_w integer);
ergibt:
sem_rueck_beur_ein | geschlecht_m | geschlecht_w --------------------+--------------+-------------- 20081 | 2116 | 779 20082 | 2564 | 893 20091 | 2311 | 814 20092 | 2796 | 974 (4 rows)
Hier ist ein Link auf das Thema in der Postgres Doku vom 9.5:
https://www.postgresql.org/docs/9.5/tablefunc.html
Mit der array_agg Funktion kann man mehrere Zeilen zu einer zusammenfassen. Das folgende Beispiel gruppiert nach Matrikelnr., Abschluss und Studiengang-Nr, so daß alle Fächer nach Fachnummer sortiert in einem Array stehen:
select S.matrikel_nr,S.studiengang_nr,D.abschluss_str, array_agg(D.stg_str) as faecher into temp tmp_1 from sos_stg_aggr S, dim_studiengang D where S.tid_stg=D.tid and S.sem_rueck_beur_ein=20142 and S.stichtag=1 group by 1,2,3 ,fach_nr order by 1,2 ,3,fach_nr;
Man kann dieses Array dann wieder ausgeben
select matrikel_nr,studiengang_nr,abschluss_str, faecher[1],faecher[2] from tmp_1;
select matrikel_nr,studiengang_nr,abschluss_str, array_to_string(faecher, ',','leer') from tmp_1;
Das letzte Argument ist optional und ersetzt NULLs durch einen String.
Mit SQL kann man leicht summieren, mit der Funktion "SUM()". Wenn Sie stattdessen multiplizieren wollen, gibt es hier
https://blog.jooq.org/how-to-write-a-multiplication-aggregate-function-in-sql/
eine gute Anleitung.
Man kann mit Postgres-Copy auch CSV Einspielen mit Headern bei der die Reihenfolge der Spalten in der CSV-Datei nicht unbedingt mit der Reihenfolge in der Datenbank übereinstimmen muss:
COPY targetTable (col2,col3,col1) FROM STDIN (FORMAT csv, DELIMITER '^',NULL ,ENCODING 'UTF8', header true)
Die Angabe von Header true führt bei COPY nur dazu, dass die 1. Zeile des CSV ignoriert wird, man muss in Klammern die Spaltennamen angeben.
Aktuell wird dies unterstützt durch Klasse de.superx.bin.GxstageCSVImport in Branch gxstage1.4_openjdk2 -
ist in der Datei db/module/gxstage/rohdaten/webservice_jars/superx5.0.jar enthalten . (Noch nicht in Master und standard SuperX5.0)
Die Klasse liest header aus 1. Zeiele und baut entsprechend COPY Befehl mit (colB,colA,colC) auf.
Die
Bei CSV-Dateien mit Anführungszeichen " wird dies standardmäßig von Postgres-Copy als Quote interpretiert, wenn nicht geschlossen, kann es zu Problemen kommen. Mit folgendem Trick kann " als Quote ignoriert werden:
Man gibt als QUOTE ein backspace Zeichen an, dass wohl nicht in CSV vorkommt QUOTE '\b'
//default quote ist ", kann aber vorkommen, daher quote Zeichen auf nicht erwartetes Backspace Oktal 10 setzen
"COPY " + targetTable + cols+ " FROM STDIN (FORMAT csv, QUOTE '\b', DELIMITER '"+delim+"',NULL ,ENCODING '"+ encoding+"'"+(header?", HEADER true":"https://superxhosting.de/wiki/index.php/null")+")";
Das folgende Kommando entlädt eine Tabelle inkl. SQL-Schema:
pg_dump $DBNAME -t costage_bw_hzb_arten > costage_bw_hzb_arten.sql
SELECT (date_trunc('month', '2017-01-05'::date) + interval '1 month' - interval '1 day')::date
AS end_of_month;
In psql können Sie die Funktionen abrufen, mit
\df
erhalten Sie eine Liste mit den Namen, und mit
select proname,prosrc from pg_proc where proname= _Name_der_Funktion_;
können Sie den Quellcode abrufen.
Der Web-PGAdmin bietet die Möglichkeit, Datenbanken ohne direkten DB-Zugriff zu verwalten. Die Kommunikation läuft über eine webbasierte Middleware (Tomcat).
Es wird zunächst ein User für die jew. Datenbank angelegt bspw. schmidt
CREATE USER schmidt WITH NOSUPERUSER PASSWORD 'password'; GRANT USAGE ON SCHEMA public TO schmidt ; GRANT SELECT ON ALL TABLES IN SCHEMA public TO schmidt ; ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO schmidt ;
Danach unter -Servername-/pgadmin4/ als AdminUser anmelden.
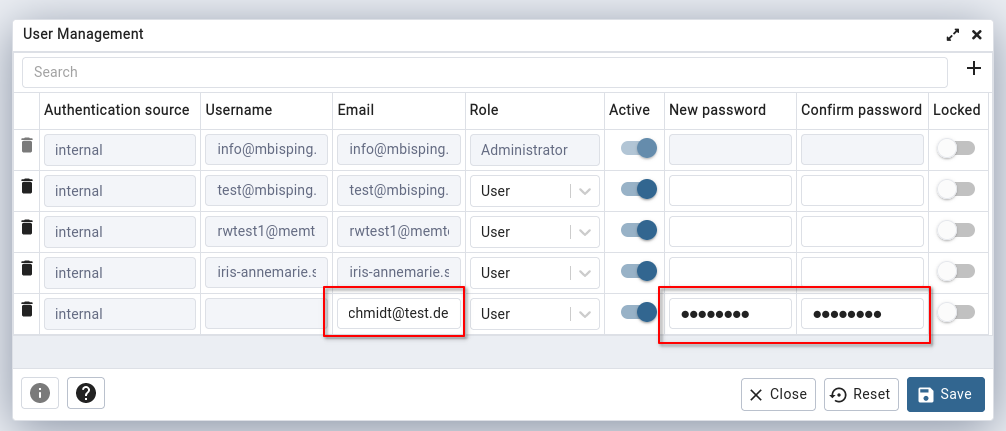
Es wird ein neuer User schmidt angelegt. Dafür wird zunächst das User Management geöffnet.
Im User Management werden die Benutzerdaten angelegt, bestehend aus einer E-Mail-Adresse und einem Passwort. Die E-Mail-Adresse darf fiktiv sein.
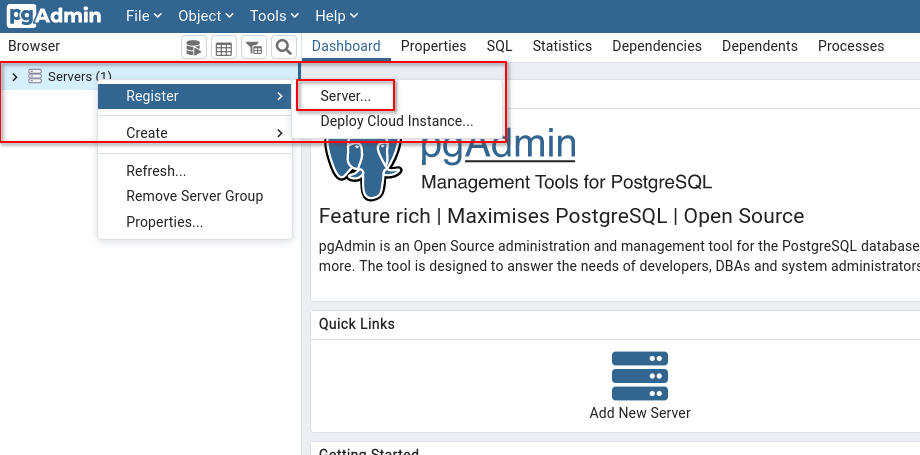
Anschließend mit dem neu angelegten User anmelden. Nach erfolreicher Anmeldung wird ein Server registriert.
Der Server bekommt einen frei wählbaren Namen.
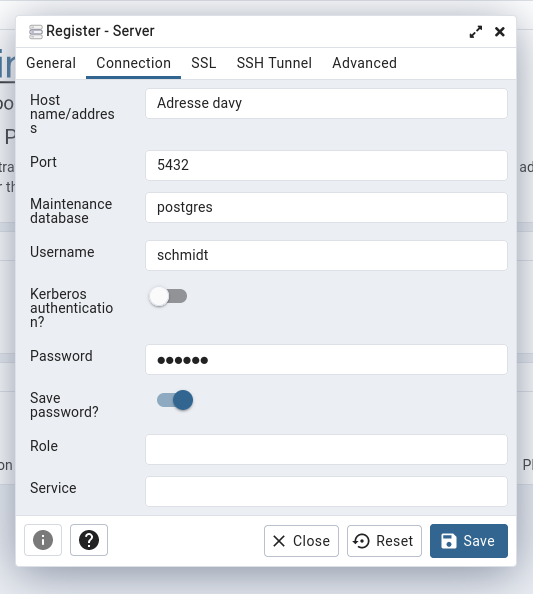
Im Reiter Connection wird die Serveradresse angegeben. Zudem werden die Benutzerdaten für den Datenbankzugriff angegeben, welche am Anfang diese Abschnittes erstellt wurden.
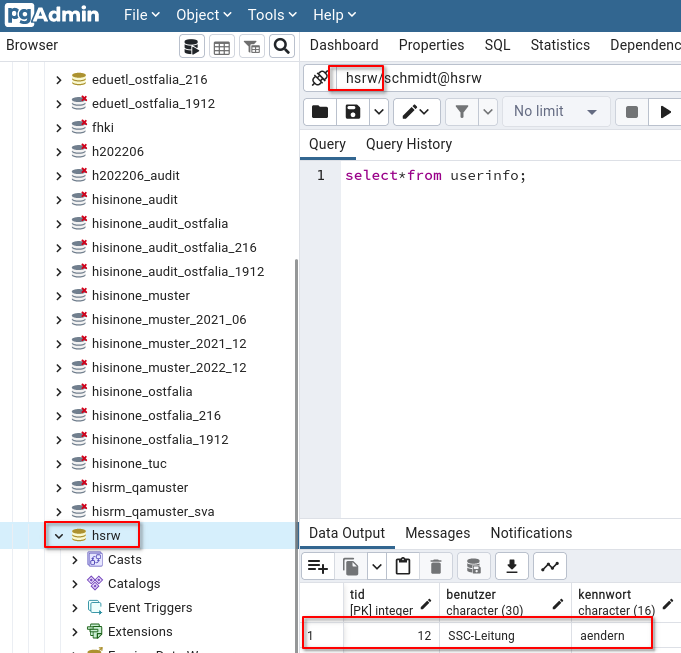
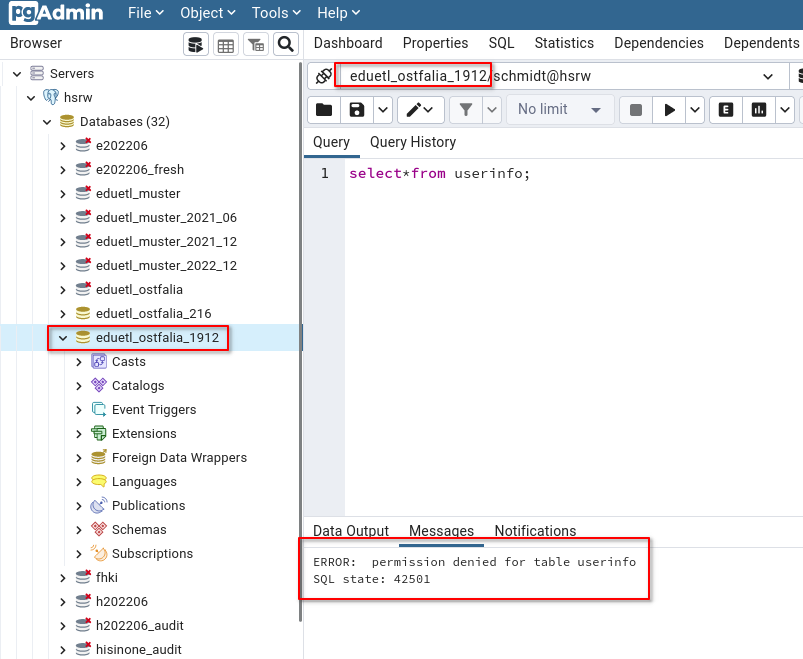
Es werden verschiedene Datenbanken aufgelistet, der User hat aber nur Zugriff auf die ihm zugehörige Datenbank.
Für andere Datenbanken wird der Zugriff verweigert.